I’ve just made some changes to the scripts that download and process the GFS and ECMWF data. They now record the end time of successful runs in a database table. Once I have a few weeks worth of data collected I’ll process the stats to give better data availability times for each model and cycle time (00/06/12/18z). That will make it easier for me to identify when runs are late. This is only for McMahon data.
You won’t see any change…I’m only mentioning this because I’ve made changes to the scripts. They’ve been tested in my test environment and I didn’t see any problems there so they should run OK in production. However, “should” sometimes becomes “didn’t” so please let me know if you notice any adverse effects in the next 24 hours.
Hi Chris,
Just curious if you had any results of data availability times.
Kindest Regards,
Tony
Thanks for reminding me. I’d forgotten I was gathering the data to do that. I’ll do a dump of the data into a spreadsheet and see what it tells me.
I will eventually produce a web page to show stats on demand but for now a manual approach will be much quicker.
Great, Thanks Chris, sounds good.
I’ve half messed up! Having extracted the data from the database I only see ECMWF records. So I’ve either forgotten to add the code to the GFS scripts. So the bad news is no GFS stats (yet) but there is good news that I can give you some ECMWF info.
The table below shows the average time, plus the earliest and latest times that the 00Z, 06Z, 12Z and 18Z ECMWF data processing runs finished on my server, i.e. the times that you’d be able to download the data. The 18Z times are for the next day. All times UTC.
|
00Z |
06Z |
12Z |
18Z |
| Average |
08:13:43 |
13:34:42 |
20:13:03 |
01:35:22 |
| Earliest |
08:08:54 |
13:33:53 |
20:08:28 |
01:33:31 |
| Latest |
08:15:24 |
13:35:44 |
20:15:15 |
01:55:45 |
The 00Z and 12Z runs take longer to appear because they are for 144 hours of data rather than 90 hours for the 06Z and 18Z runs.
My interpretation of the data suggests that if you time your runs that use ECMWF data at:
00Z - 08:20
06Z - 13:40
12Z - 20:20
18Z - 01:40
…then in most cases you’ll have the latest data available. The only exception was a single 18Z run that was later than all others by about 15 minutes so you’d have missed that one.
Now to figure out what I’ve done wrong with the GFS stats collection.
PS. I’ve also just discovered that if you want to include tabular data in a post, just copypasta from a spreadsheet and it converts the format automatically!
I’ve fixed the non-existent GFS stats. Actually they were disappearing GFS stats.
For those interested, I’d messed up the primary key on the stats data table. It should have been ‘run_id+run_type’ but I’d defined it as ‘run_id’ only. The GFS runs always finish first, so a stats record for ‘2023-08-04-00’ GFS run is added to the database. Later on the ECMWF 2023-08-04-00 run finishes and a stats record is added. However, because the primary (unique) key was defined incorrectly instead of adding a record it overwrites the GFS record.
Programmer 1 DBA 0 - Trouble is they’re both me 
Now I just need to wait a few weeks to get some GFS stats to process.
Edit: Some hours later I’ve confirmed the existence of a GFS stats record so my fix has worked.
I now have 12 days of GFS stats and they’re not very helpful, i.e.
00z run - Fastest 5h15m Slowest 6h54m
06z run - Fastest 5h11m Slowest 7h30m
12z run - Fastest 5h12m Slowest 6h49m
18z run - Fastest 5h17m Slowest 6h35m
The fastest times are all pretty much in line at about an average of 5h13m after the run cycle time (00/06/12/18).
The slowest times show a lot of variability though and I don’t have data to help me understand why they are so variable. A very quick look at the GFS data source suggests that on at least 2 runs where I’m seeing later than normal data availability from my system the GFS files were available at about the normal time (approx 4.5 hours after the cycle time). That suggests that the delay is somewhere on my system/in my code.
What I can’t currently understand is why on many occasions my code can download and process the data within about 40 minutes of NWS making the source data available and other times it takes much longer? Same sever, same network connection (although the network doesn’t seem to be relevant). I could understand if a particular run time was slower, e.g. 00Z, when I might have backups running, but I’m not running backups all the time and in any case I don’t believe I’m running any at times when GFS processing would be active. I can also understand that perhaps some of the runs become much longer if they clash with the start of an ECMWF processing run, but that data arrives much later than GFS so most GFS runs should be able to run to completion long before the ECMWF data starts to become available for me to download it.
I’ll have to add some more stats collection to my code to try to work out what’s causing some runs to be slower than others.
Hi Chris,
Thanks for all your hard work and checking.
Sorry I cannot help answer any of the questions for you.
Just one wild one though, I still run my GFS Maps and normally they fly through quickly, however every now and then (some times more often) they fail some maps resulting in an error from my memory relating to something about “Malformed or inaccessible DAP DATADDS” Maps get drawn though incomplete. I have never crossed checked if one of your Runs are late when I get this issue, could be way off and non related, though be curious !
My thought being is your script working hard to fix the malformed data ?
Kind Regards,
Tony
You’re using a different method of getting data than I am (I process raw GRIB2 data). I don’t know if the DAP DATADDS method accesses data from the same GRIB2 files as I use though. I guess that if the underlying forecast run is late then everything downstream would be late, but beyond that I don’t know how common the data paths are.
There have been times when data files were corrupt but I can’t say I’ve seen any recently. In any case if Sam’s data is available before mine then that suggests the data isn’t corrupt. Also there is more than one place to download the GRIB2 files from (or used to be and DATADDS may have access to an internal path) and I’ve known times when source 1 was corrupt but the same file on source 2 wasn’t, so there might not be a correlation between DATADDS and my mechanism.
I’ve added logging of some more timing points into my GFS script (I’ll back-fit to ECMWF later on). These should tell me:
- The time when it appears that the GFS data is fully available
- The time when I finished downloading the data
- The time I completed processing the data
Also the way I’ve done it will tell me if any runs repeat, i.e. I’ll know if a run crashed out during downloading or processing and had to be repeated.
I’ll need to gather stats for a week or two now to see if I can see any pattern emerging.
Brilliant thanks Chris, Greatly Appreciated.
From the first 3 runs since I put the extra logging points in I’m seeing this…
- The data becomes available to me about 4h35m after the run time, so 04:35 for the 00z run.
- It takes 1 to 5 minutes to download the data
- Processing takes about 35 minutes
- Data is available for you to download between 5h10m and 5h20m after the run time.
I think originally it was said that the data would be available about 4h30m after the run time so this is a bit later than that. I’m wondering whether this happened when we switched from using 1degree to 0.5degree data. Maybe as there’s more data it takes longer to become available?
Having said that, I’m wondering whether there’s any real benefit in grabbing and using the data as soon as it becomes available. The GFS (and ECMWF) data is provided in 3 hourly intervals, so 00z, 03z, 06z, 09z, etc. If you calculate as soon as the data becomes available then the only way for WxSim to estimate the advection data is to use linear interpolation between the 03z and 06z values. That introduces a, probably small, margin of error because the conditions won’t change linearly between the two time points.
I’m wondering whether the best strategy is to download at say 05:50 after the run time (05:50, 11:50, 17:50 and 23:50) and then time your forecasting runs for 6 hours after run time. You can then use the actual real GFS values for 6 hours and also have relatively recent local data. Ideally I guess it would be better if WxSimate allowed you to schedule different downloads at different time, i.e. GFS at 05:50 then local data at 05:59 to get the best of both sets of data.
ECMWF timing is an additional issue in all of this because that adds yet another time point into the mix.
This is just an initial thought after only three sets of data. I still haven’t seen any delayed GFS data sets yet to figure out why it’s sometimes much later than expected.
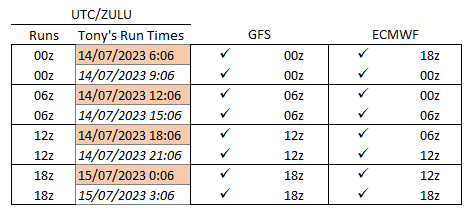
Hi Chris,
I have been running the following times for years and years (posted them many times before), in fact in the early days I used to change all my scripts and crons every DST change to maintain the same 6 hr after GFS Run times, though a few years back decided to not bother, which means in DST I run 7 hours after GFS Run Times.
Aha, (correction). I always make that mistake (7hrs) should be (5hrs) which means that everything now seems to be running roughly an hour later than years ago.
So come my DST change in 40 days time I will most likely have issues this year.
Here is my adjusted Time Chart, explains that correction better I hope.
I’ve now got 5 days of stats in my spreadsheet and the numbers have been pretty consistent so far, i.e.
- On average the data becomes available 4h36m after the run start time (00/06/12/18z) with the earliest being 4h32m and the latest 4h43m.
- My script runs every 5 minutes so there can be up to a 5 minute delay after the data becomes available before I will start to download. The average delay before I start to download is 2 minutes, so not too bad.
- An average download of all the data I need takes 2m26s, with a minimum of 1m1s to a maximum of 5m2s. That seems quite a wide variation but I’m dragging the data across quite a few thousand miles of the Internet and also many other people will also be downloading the data at the same time so I expect a little variability.
- Once I have the data I need it takes on average 33m50s to unpack the 500MB of data, extract the 40-ish data values (times 81 for each 3 hourly interval) for each of about 76,000 locations (about 250 million data values in total) and store approx 76,000 records in the database. That all takes a while. Minimum time to run the import is 32m12s and maximum time is 35m43s.
- Data is available for download, on average, at 5h14m17s past the run time (00/06/12/18z UTC) with the soonest being 5h10m12s and the latest being 5h20m23s.
I’ve discovered one edge case anomaly so far. I check for the existence of the last data file I need to download before starting to download the first file (there are 81 files to download). In one case it appears that the last file took longer for NWS to upload than normal so the file existed but was incomplete when I checked if it existed. So I started the download before the full data set was available. I think I know how I can fix this, but in this particular case my scripts seemed to handle it without any problem so it didn’t break anything.
So after 5 day of stats gathering, if you download the data 5h30m after the (UTC) run start time of 00z/06z/12z/18z then you should get the latest GFS data.
I’m still gathering stats, but at the moment it’s pretty boring with no obvious causes for concern. It’s a manual job at the moment but I’ll see if I can automate more of it now that I’ve got a better idea of the info I need to generate.
Hi
so looking at this data above and when the GFS and ECMWF data come sin and when WXsim runs, what are the best time do you think to run wxsim to get a better forecast using the latest data?
At present I run my forecast at the following times:
06:00, 10:00, 14:00, 18:00, 22:00
Thanks
I’ve not started to do the same kind of analysis for ECMWF yet, but I’m pretty sure it’s going to end up confusing things!
Multiples of 6 hours (from 00:00) in UTC are good for getting the latest GFS data, but at those times you’ll always get ECMWF data that’s 6 hours older than the GFS data.
My current best guess at ECMWF data availability times is 8h30m after run time for 00/12z runs and 8h after run time for 06/18z runs (the 00/12z runs have more hours of data which is why they’re a bit later).
If that’s correct then the sweet spots for having both sets of data as close as possible to each other are to run when the ECMWF becomes available…GFS will be 2-2.5 hours old by that time but that’s (probably) better than having ECMWF 6 hours old if you run after GFS becom available. So if you’re doing 4 runs per day I’d go for : 08:30, 14:00, 20:30 and 02:00 (all UTC). This seems to be the best compromise. That might shift a bit when I’ve got some ECMWF stats available, but I’ve not modified the scripts yet to even start gathering the info I need.
After 10 days of stats in my spreadsheet the times are looking pretty consistent, i.e.
- On average the data becomes available 4h35m after the run start time (00/06/12/18z) with the earliest being 4h32m and the latest 4h43m.
- The average delay between data available and the download starting is 2m7s, so not too bad and reasonable for a script running every 5 minutes.
- An average download of all the data I need takes 2m41s, with a minimum of 1m2s to a maximum of 7m19s.
- Once I have the data I need it takes on average 33m57s to unpack, extract, calculate and store the data. Minimum time to run the import is 32m12s and maximum time is 35m43s.
- Data is available for download, on average, at 5h14m24s past the run time (00/06/12/18z UTC) with the soonest being 5h09m14s and the latest being 5h21m36s. So no huge excursions in availability time.
1 Like